There is an instrument which measures the vibrations produced by the flow of air expelled through the vocal tract, which gives graphic “transcripts” of what is pronounced. These are called spectrograms.
For example, the spectrogram below represents the vowel [ a ] pronounced very briefly in isolation. The X axis represents milliseconds and the Y axis represents changes in frequency. The air will go through the vocal tract and make its cords vibrate, and then through the mouth in which the articulators (tongue, teeth and lips) will have a specific position. This will result in a particular vibration of the air, transcribed into a specific shape on the spectrogram.

The next spectrogram transcribes the vibration of the air produced by saying the same word, “Balzac” (the French author), six times in six different sentences by the same speaker in the same meeting. The first instance of the word is circled in orange.
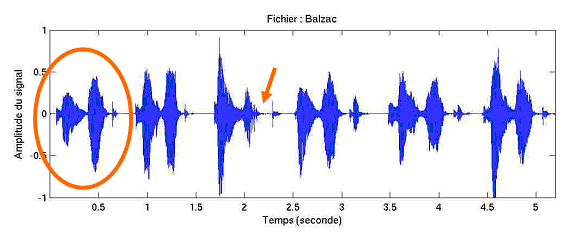
You can see that there are no pauses, i.e. no stretches of flat line, between the constitutive sounds of each repeated word, except between the [ a ] and the final [ k ], as you can see most clearly in the third instance under the orange arrow. Note however that this silence is not perceived as such but as a part of the sound [ k ]. (When we utter the sounds [ p ], [ t ], or [ k ], we actually utter a piece of silence followed by an explosion, i.e. we accumulate air in the mouth and then suddenly open the mouth to release the air – the silence is actually part of the “sound” and, if it is removed, the sound is not recognized.)
In any case, it is impossible to determine when one sound finishes and the next one starts, because the beginning of each sound overlaps with the end of the previous one and its own end overlaps with the beginning of the next one. This is referred to as co-articulation.
Moreover, you can see that there are sometimes big variations across the six instances of this word, even though they were said by the same person during the same meeting. This is because the characteristics of each instance of the word vary slightly depending of the context. For example, it is likely that the third and the sixth instances started new sentences because, as you can see, the beginnings of these two instances were produced with more energy (i.e. have a higher amplitude) than the others.
In short, the same word is never pronounced twice exactly in the same way, even by the same person. There are even more variations between instances of the same “sound” across different words. For example, the sound [ b ] is not produced in exactly the same way in [ bat ] and [ table ] because the sounds which follow and/or precede [ b ] overlay it.
We learn to discount these variations because they have no bearing on the meaning. They are called allophonic variations and the phenomenon itself is called allophony.
As we said, some learners with dyslexia are oversensitive to co-articulation and to allophonic variation. Consequently they could be building fuzzy representations of the “sounds” of the language.
(See for example the studies of Serniclaes, Van Heghe, Mousty, Carré & Sprenger-Charolles, and of Sprenger-Charolles & Serniclaes – the full references are cited in Sources at the end of the Section.)